3D shape from a single image
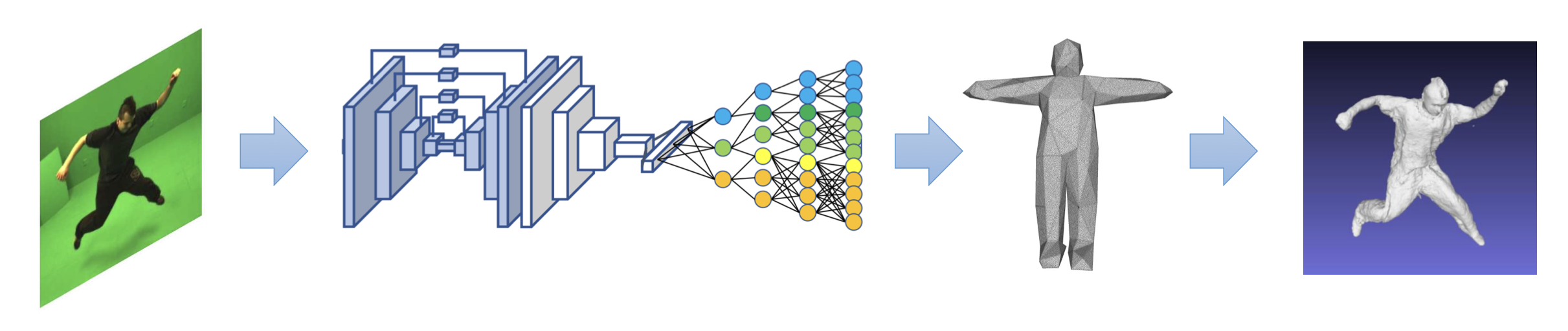
Detailed 3D shapes of the human body reveal personal characteristics that cannot be captured with standard 2D pictures. Such information is crucial for many applications in the entertainment industry (3D video), business (virtual try-on) or medical use (self-awareness or rehabilitation). Methods that can efficiently reconstruct detailed 3D human shapes in unconstrained environments are needed. In this research project we focus on the task of detailed 3D human body reconstruction in a single shot with a standard RGB camera. Learning to reconstruct complete 3D shapes of humans wearing loose clothes with using implicit representation discretized in cubic voxels is largely adopted by the community. However strong limitations remains: resolution vs memory consumption trade-off; no texture. We introduce a new implicit representation using tetrahedra that allows for direct formulation while significantly reducing the memory consumption.
PAPER CODE
Animatable avatars
Digital humans are the key to create immersive and lively virtual environments. Human avatars should not only possess realistic geometric details but they should also have the ability to be animated in the digital world with realistic motion of muscles and clothes, and at high frame rate. Currently, only professionals and artists can make realistic animatable avatars by using offline softwares like Maya or Blender, because it requires special skills, such as skeleton construction, skinning weights and physics (e.g. hair, clothes, etc...). A wide variety of techniques have been proposed to automate the process of generating animatable avatars, such as using examples of 3D posed meshes, captured 4D data or multi-view images. We argue that these methods require either heavy data preparation steps or time consuming post-process to transform the output into usable 3D meshes. What we really need, instead, is a simplified data preparation pipeline and output that can be directly used in standard animation software. We address this here for the first time.
Human pose estimation
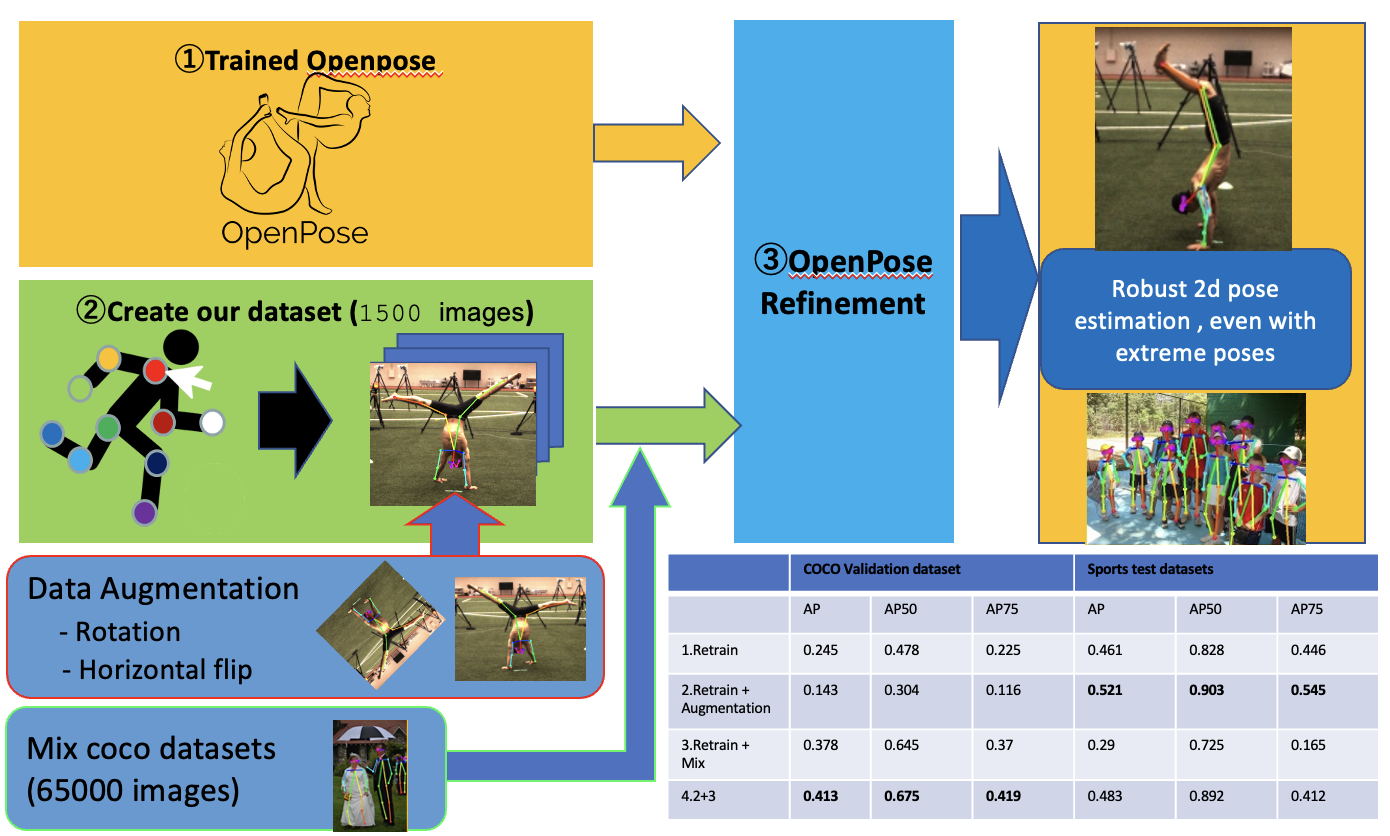
3D marker-less motion capture can be achieved by triangulating estimated multi-views 2D poses. However, when the 2D pose estimation fails, the 3D motion capture also fails. This is particularly challenging for sports performance of athletes, which have extreme poses. In extreme poses (like having the head down) state-of-the-art 2D pose estimator such as OpenPose do not work at all. In this work, we propose a new method to improve the training of 2D pose estimators for extreme poses by leveraging a new sports dataset and our proposed data augmentation strategy.
PAPER
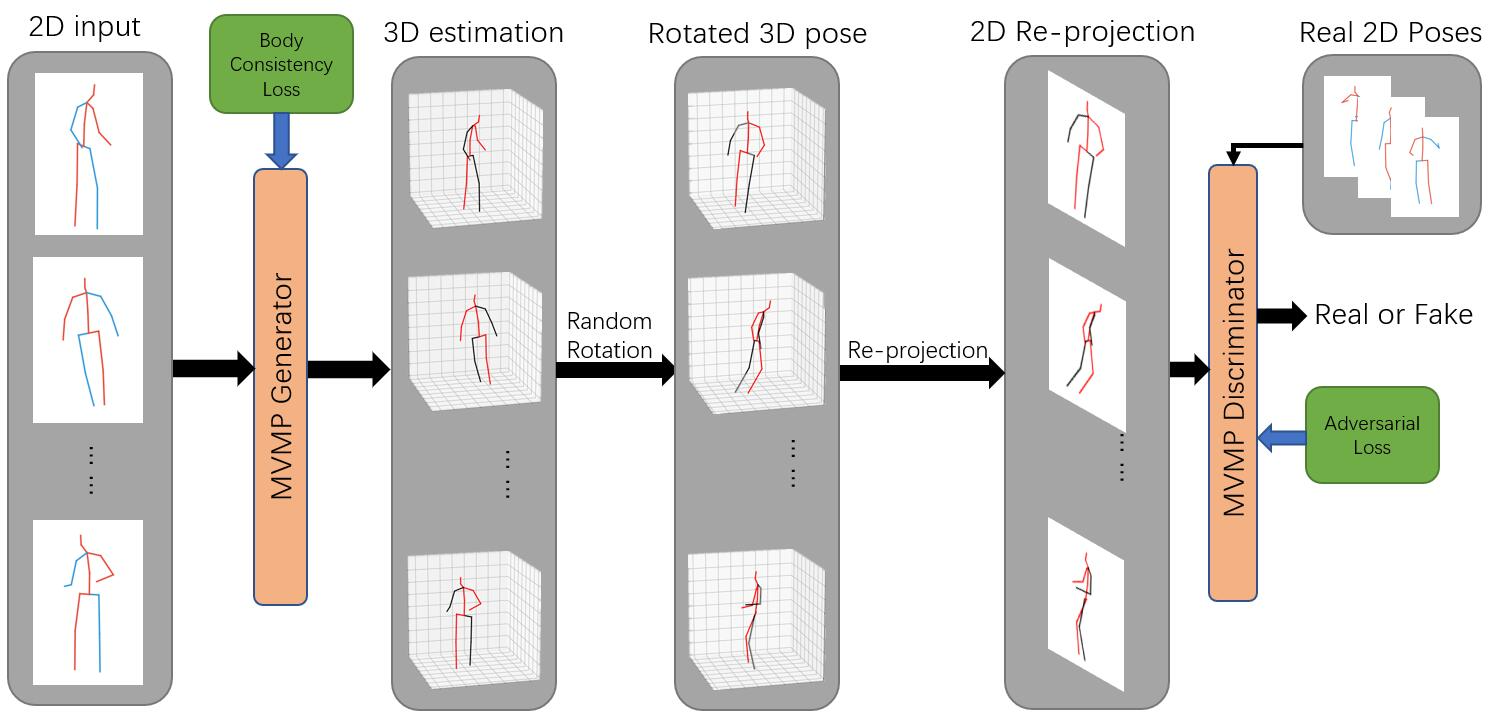
3D human pose estimation from a single 2D video is an extremely difficult task because computing 3D geometry from 2D images is an ill-posed problem. Recent popular solutions adopt fully-supervised learning strategy, which requires to train a deep network on a large-scale ground truth dataset of 3D poses and 2D images. However, such a large-scale dataset with natural images does not exist, which limits the usability of existing methods. While building a complete 3D dataset is tedious and expensive, abundant 2D in-the-wild data is already publicly available. As a consequence, there is a growing interest in the computer vision community to design efficient techniques that use the unsupervised learning strategy, which does not require any ground truth 3D data. Such methods can be trained with only natural 2D images of humans. In this paper we propose an unsupervised method for estimating 3D human pose in videos. The standard approach for unsupervised learning is to use the Generative Adversarial Network (GAN) framework. To improve the performance of 3D human pose estimation in videos, we propose a new GAN network that enforces body consistency over frames in a video.
PAPER
3D pedestrian detection
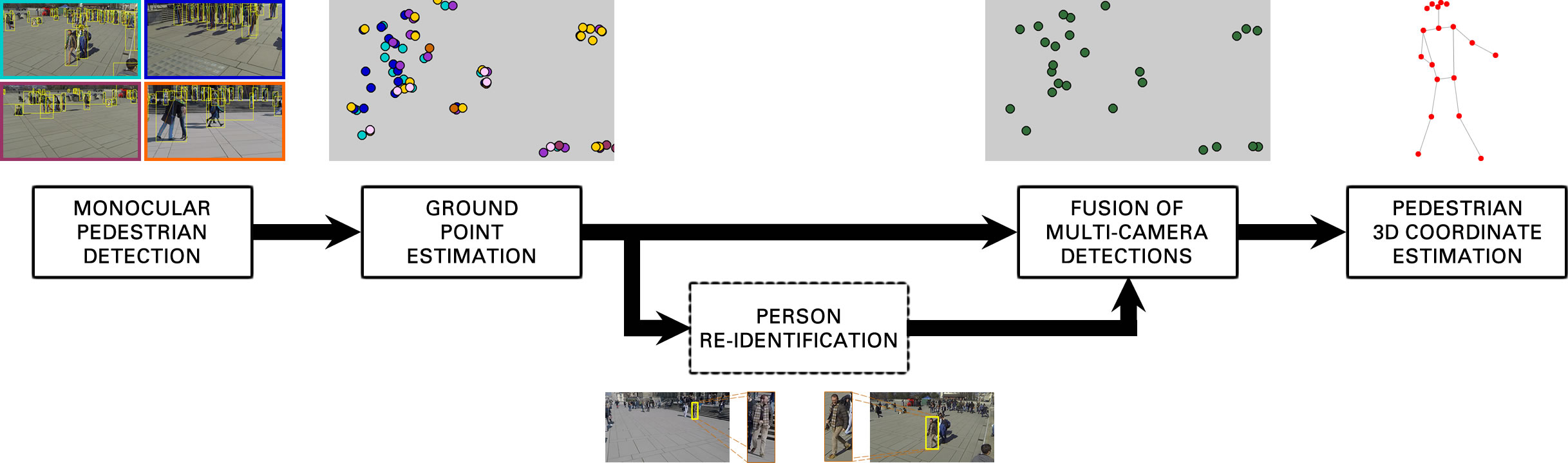
Pedestrian detection is a critical problem in many areas, such as smart cities, surveillance, monitoring, autonomous driving, and robotics. AI-based methods have made tremendous progress in the field in the last few years, but good performance is limited to data that match the training datasets. We present a multi-camera 3D pedestrian detection method that does not need to be trained using data from the target scene. The core idea of our approach consists in formulating consistency in multiple views as a graph clique cover problem. We estimate pedestrian ground location on the image plane using a novel method based on human body poses and person's bounding boxes from an off-the-shelf monocular detector. We then project these locations onto the ground plane and fuse them with a new formulation of a clique cover problem from graph theory. We propose a new vertex ordering strategy to define fusion priority based on both detection distance and vertex degree. We also propose an optional step for exploiting pedestrian appearance during fusion by using a domain-generalizable person re-identification model. Finally, we compute the final 3D ground coordinates of each detected pedestrian with a method based on keypoint triangulation. We evaluated the proposed approach on the challenging WILDTRACK and MultiviewX datasets. Our proposed method significantly outperformed state-of-the-art in terms of generalizability. It obtained a MODA that was approximately 15\% and 2\% better than the best existing generalizable detection technique on WILDTRACK and MultiviewX, respectively.
PAPER
Populating VR spaces with digital humans
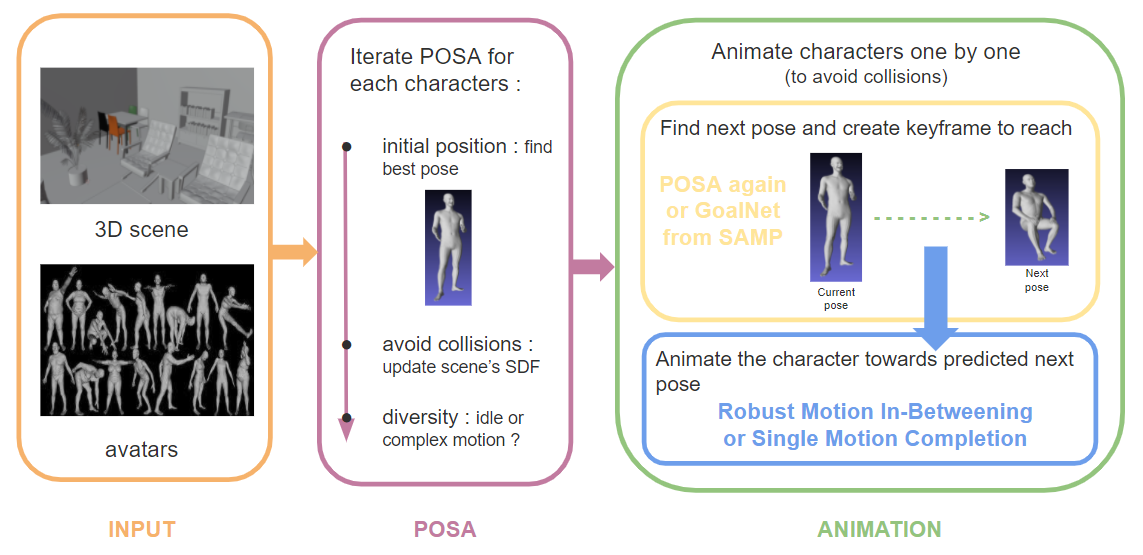
Detailed animations of human avatars must be included into the VR system to study the impact of the design on the people
lifestyle. We will develop a new AI-based approach for animated 3D human avatar generation in a given 3D scene. To learn
how to animate and consistently deform the human body and clothes we must first build a new 4D (3D+time) human body and
cloth database.
With our 4D human dataset we will design a network to generate realistic animation of humans wearing loose clothes. This
will allow us to populate scenes with diverse human avatars performing daily activities.